
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 날코딩으로 알고 짜는 딥러닝
- 딥러닝 교차엔트로피
- 딥러닝 교차 엔트로피
- 신경망
- 인공지능
- DBMS
- 퍼셉트론
- 자료구조 알고리즘
- 파라미터
- 파이썬 딥러닝
- 엔트로피
- 자연어처리
- 편미분
- 선형 리스트
- 순차 자료구조
- 딥러닝
- 노드
- 컴퓨터구조
- DB
- 연결 자료구조
- 회귀분석
- 교차 엔트로피
- lost function
- 리스트
- 오퍼랜드
- 뇌를 자극하는 알고리즘
- 자료구조
- 단층 퍼셉트론
- 확률분포
- 단층퍼셉트론
- Today
- Total
YZ ZONE
[ 컴퓨터구조 ] 5.5 캐시 기억장치 본문
캐시 기억장치
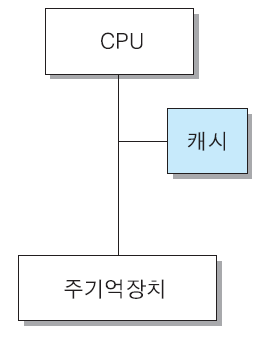
▣ 캐시 기억장치 사용 목적
▪ CPU와 주기억장치의 속도 차이로 인한 CPU 대기 시간을 최소화 시키 기 위하여 CPU와 주기억장치 사이에 설치하는 고속 반도체 기억장치
▣ 특징
▪ 주기억장치(DRAM)보다 액세스 속도가 더 높은 칩(SRAM) 사용
▪ 가격 및 제한된 공간 때문에 용량이 적다
▣ 캐시 적중(cache hit)
▪ CPU가 원하는 데이터가 캐시에 있는 상태
▣ 캐시 미스(cache miss)
▪ CPU가 원하는 데이터가 캐시에 없는 상태
▪ 이 경우에는 주기억장치로부터 데이터를 읽어옴
▣ 적중률(hit ratio)
▪ 캐시에 적중되는 정도(H)

▣ 캐시의 미스율(miss ratio) = (1 - H)
▣ 평균 기억장치 액세스 시간(Ta) :
Ta = H × Tc + (1 - H) × Tm
단, Tc는 캐시 액세스 시간, Tm은 주기억장치 액세스 시간
캐시 적중률과 평균 기억장치 액세스 시간의 관계

▣ 캐시의 적중률이 높아질수록 평균 기억장치 액세스시간은 캐시 액세스 시간에 접근
▣ 캐시 적중률은 프로그램과 데이터의 지역성(locality)에 따라 달라짐 CPU가 원하는 데 이터가 캐시에 있는 상태
지역성(locality)
▣ 시간적 지역성(temporal locality)
▪ 최근에 액세스된 프로그램이나 데이터가 가까운 미래에 다시 액세스 될 가능성이 높다
▣ 공간적 지역성(spatial locality)
▪ 기억장치내에 인접하여 저장되어 있는 데이터들이 연속적으로 액세스 될 가능성이 높다
▣ 순차적 지역성(sequential locality)
▪ 분기(branch)가 발생하지 않는 한, 명령어들은 기억장치에 저장된 순 서대로 인출되어 실행된다
캐시 설계에 있어서의 공통적인 목표
▣ 캐시 적중률의 극대
▣ 캐시 액세스 시간의 최소화
▣ 캐시 미스에 따른 지연 시간의 최소화
▣ 주기억장치와 캐시 간의 데이터 일관성 유지 및 그에 따른 오버헤드의 최소화
캐시의 크기 / 인출 방식
▣ 캐시의 크기(용량)
▪ 용량이 커질수록 적중률이 높아지지만, 비용이 증가
▪ 용량이 커질수록 주소 해독 및 정보 인출을 위한 주변 회로가 더 복잡해지기 때문에 액세스 시간이 다소 더 길어진다
▣ 인출 방식
▪ 요구 인출(demand fetch) 방식
➢필요한 정보만 인출해 오는 방법
▪ 선인출(prefetch) 방식
➢필요한 정보 외에 앞으로 필요할 것으로 예측되는 정보도 미리 인출
➢지역성이 높은 경우에 효과가 크다.
주기억장치와 캐시의 조직
* 주기억장치 블록(K개의 단어들로 구성) : 하나의 캐시 라인(cache line)에 적재
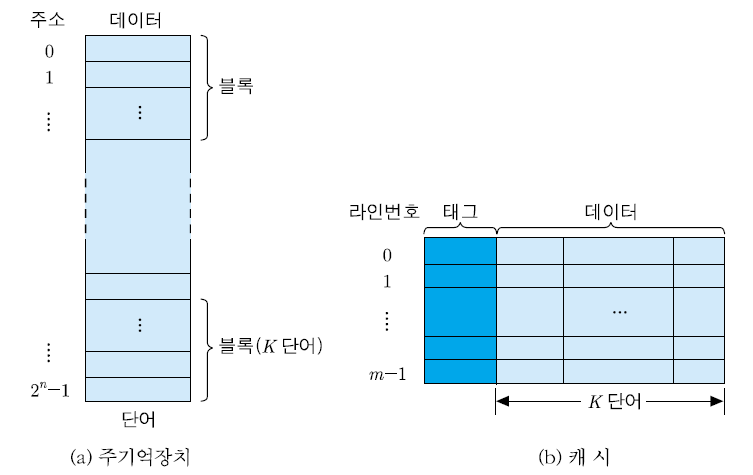
▣ 블록(block)
▪ 주기억장치로부터 동시에 인출되는 정보들의 그룹 ▪주기억장치용량=2n 단어,블록=K단어
➢블록의 수 = 2n/K 개
▣ 라인(line)
▪ 캐시에서 각 블록이 저장되는 장소
▣ 태그(tag)
▪ 라인에 적재된 블록을 구분해주는 정보
사상 방식
▣ 사상 방식
▪ 각 주기억장치 블록이 어느 캐시 라인에 적재될 것인 지를 결정해 주는 방식으로서, 캐시 내부 조직을 결정
➢직접 사상(direct mapping)
➢완전-연관 사상(fully-associative mapping)
➢세트-연관 사상(set-associative mapping)
▣ 직접 사상
▪ 각 주기억장치의 블록이 지정된 하나의 캐시 라인으로만 적재됨
▪ 주기억장치 주소 형식
➢태그 필드(t 비트) : 태그 번호(라인에 적재되어 있는 블록의 번호)
➢라인 번호(l 비트) : 캐시의 m = 2l 개의 라인들 중의 하나를 지정
➢단어필드(w비트):각블록내2w 개단어들중의하나를구분
▪주기억장치의블록j가적재될수있는캐시라인의번호i : i = j mod m
단, j:주기억장치블록번호,m:캐시라인의전체수
라인을 공유하는 주기억장치 블록들
▣각캐시라인은2t 개의블록들에의하여공유
▣ 같은 라인을 공유하는 블록들은 서로 다른 태그를 가짐

직접 사상 캐시의 조직

직접 사상 캐시의 동작 원리
▣ 캐시로 기억장치 주소가 보내지면, 그 중 l 비트의 라인 번호 를 이용하여 캐시의 라인을 선택
▣ 선택된 라인의 태그 비트들을 읽어서 주소의 태그 비트들과 비교
▪ 두 태그값이 일치하면(캐시 적중) ➔ 주소의 w 비트들을 이용하여 라 인내의 단어들 중에서 하나를 인출하여 CPU로 전송
▪ 태그값이 일치하지 않는다면(캐시 미스)
➢주소를 주기억장치로 보내어 한 블록을 액세스
➢인출된 블록을 지정된 캐시 라인에 적재하고, 주소의 태그 비트들을 그 라인의 태그 필드에 기록
➢만약 그 라인에 다른 블록이 이미 적재되어 있다면, 그 내용은 지워지고 새로이 인출된 블록을 적재하고 태그도 갱신
직접 사상 캐시의 예
▪ 주기억장치 용량 = 128( 27) 바이트
▪ 주기억장치 주소 = 7 비트 (바이트 단위 주소 지정) ▪ 블록 크기 = 4 단어 = 4 바이트
→ 주기억장치는 128/4 = 32 개의 블록들로 구성 ▪ 캐시 용량 = 32 바이트
▪ 캐시 라인 크기 = 4 바이트 (블록 크기와 동일) ▪전체캐시라인의수, m=32/4=8개
➔기억장치 주소 형식

▣ 각 기억장치 블록이 공유하게 될 캐시 라인 번호
i = j mod 8


[예제 5-2] 직접 사상 캐시에서의 적중 검사 예
(1) 0101000 (2) 0001101 (3) 1110111 (4) 1011010
<풀이>
(1)캐시 미스→2번 라인의 데이터 필드 : ‘info’, 태그 : 01
(2)캐시 적중 : 3번 라인에 적재되어 있음
(3)캐시 미스→5번 라인의 데이터 필드 : ‘tech’, 태그 : 11
(4)캐시 적중 : 6번 라인에 적재되어 있음
[참고: 단어 필드의 값 이 ’10’이므로, 만약 읽기 동작이라면 ‘arch’ 중에서 세 번째 단어인 ‘c’가 CPU로 읽혀진다.]
직접 사상 캐시의 장단점
[장점]
▪ 하드웨어가 간단하고, 구현 비용이 적게 든다
[단점]
▪ 각 주기억장치 블록이 적재될 수 있는 캐시 라인이 한 개 뿐이기 때문 에, 그 라인을 공유하는 다른 볼록이 적재되는 경우에는 overwrite되 거나 swap-out 됨
'IT > 컴퓨터구조' 카테고리의 다른 글
| [ 컴퓨터구조 ] 5.5.3 캐시 기억장치 (계속) (0) | 2023.02.08 |
|---|---|
| [ 컴퓨터구조 ] 5.5.2 캐시 기억장치 (계속) (0) | 2023.02.08 |
| [ 컴퓨터구조 ] 5.4 기억장치 모듈의 설계 (0) | 2023.02.06 |
| [ 컴퓨터구조 ] 5.3 반도체 기억장치 (0) | 2023.02.06 |
| [ 컴퓨터구조 ] 5.2 계층적 기억장치시스템 (0) | 2023.02.06 |



