
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 순차 자료구조
- 단층 퍼셉트론
- 엔트로피
- 인공지능
- 딥러닝 교차엔트로피
- 딥러닝 교차 엔트로피
- 신경망
- 단층퍼셉트론
- 컴퓨터구조
- 확률분포
- 선형 리스트
- 교차 엔트로피
- 딥러닝
- 자료구조 알고리즘
- DB
- DBMS
- 퍼셉트론
- 파라미터
- 오퍼랜드
- 자료구조
- 회귀분석
- 편미분
- 노드
- 리스트
- 뇌를 자극하는 알고리즘
- 연결 자료구조
- 파이썬 딥러닝
- 자연어처리
- lost function
- 파이썬 날코딩으로 알고 짜는 딥러닝
- Today
- Total
YZ ZONE
[자연어처리] 5. 어휘 분석 본문
어휘 분석: 단어의 구조를 식별하고 분석을해 어휘가 어떤 의미와 품사를 가지는지 연구
형태소 분석
: 더 이상 분해될 수 없는 최소한의 의미 단위인 형태소를 자연어의 제약 조건과 문법 규칙에 맞춰 분석하는 것 ex) 컴퓨터를 = 컴퓨터 + 를 → 각각 의미를 지님
형태소 분석 절차
- 단어에서 최소 의미를 포함하는 형태소 후보로 분리ex) 한국어(Korean)는 = 한국어 + ( + Korean + ) + 는-같은 형태소열에서 분석될 수 있는 후보
나는 = 날 + 는 (fly의 의미) - ex) 나는 = 나 + 는 (me의 의미)
- 한국어에서 형태소가 연결될 때, 형태소의 변형이 일어나기 때문에 형태소 원형의 복원이 필요함
- 형태소 분석의 처리 대상인 어절(또는 단어)은 하나 이상의 형태소가 연결된 것. ‘형태소열’이라고도 함.
- 형태론적 변형이 일어날 형태소의 원형 복원 및 형태소품사쌍 생성형태소와 그 형태소의 품사를 쌍으로 나타낸 것을 형태소품사쌍이라함
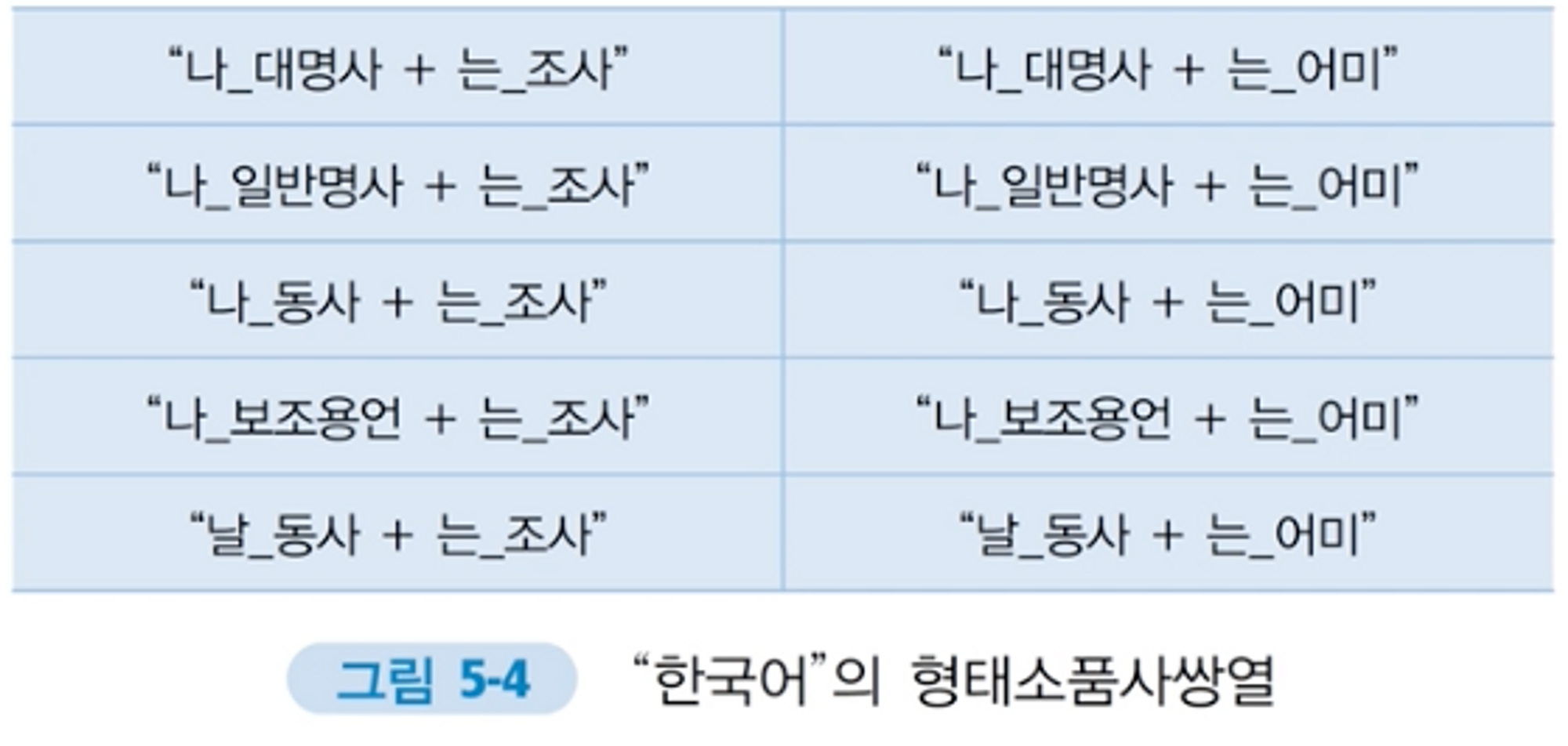
나-: (나_대명사),(나_명사),(나_동사),(나_보조용언) - ex) 한국어- :(한국어_고유명사)
- 형태소는 하나 이상의 품사를 가질 수 있어, 하나의 형태소는 하나 이상의 형태소와 품사의 쌍으로 표현됨
- 단어와 사전들 사이의 결합조건에 따라 옮은 분석 후보를 선택
ex) “나는”에 대한 형태소품사쌍열 후보군 중 선택
영어 형태소 분석
영어에서 최소 단위의 의미를 갖는 기본 단위는 단어.
어간추출(stemming),표제어추출(lemmatization)을 통해 쉽게 형태소 파악 가능.


일반적으로 영어의 형태소는 접사. 접미사(앞) 접두사(뒤).
접사를 제거했을 때 의미가 바뀌는 단어들 존재하며, 최소한의 의미를 갖고있는 형태소를 찾아 원형 분석 필요함

품사 태깅
품사 태깅이란 같은 단어의 중의성을 해결하기 위해 부가적으로 언어의 정보를 부착하는 것을 뜻합니다.
품사: 단어의 기능, 형태, 의미에 따라 나눈 것
태깅: 같은 단어에 대해 의미가 다를 경우(중의성)를 해결하기 위해 부가적인 언어의 정보를 부착

품사 태깅 접근법
- 규칙 기반의 접근법 (문법?)
전문가가 수동으로 규칙을 만들어서 함.
언어 정보에서 생성되는 규칙 형태로 표현, 이를 적용해 태깅 수행.
장점: 품사 사이 관계 외의 어절에 대해 높은 정확도를 나타내기 때문에 통계 기반 접근법으로 다루지 못하는 부분에 대해 교정이 가능
긍정정보, 부정정보, 수정정보로 중의성을 해결하고 태깅을 부착하는 방법
긍정 정보: 문장에서 선호되는 어휘 태그에 대한 언어 지식. [가 or 나] → 가 [다 or 라]
부정 정보: 특정 문장에서 배제되는 어휘 태그에 대한 언어 지식. 가 ? 나 → not 다
수정 정보: 오류 교정. 잘못된 정보 입력시 수정될 정보에 대한 지식 A:가 → 나
- 통계 기반의 접근법
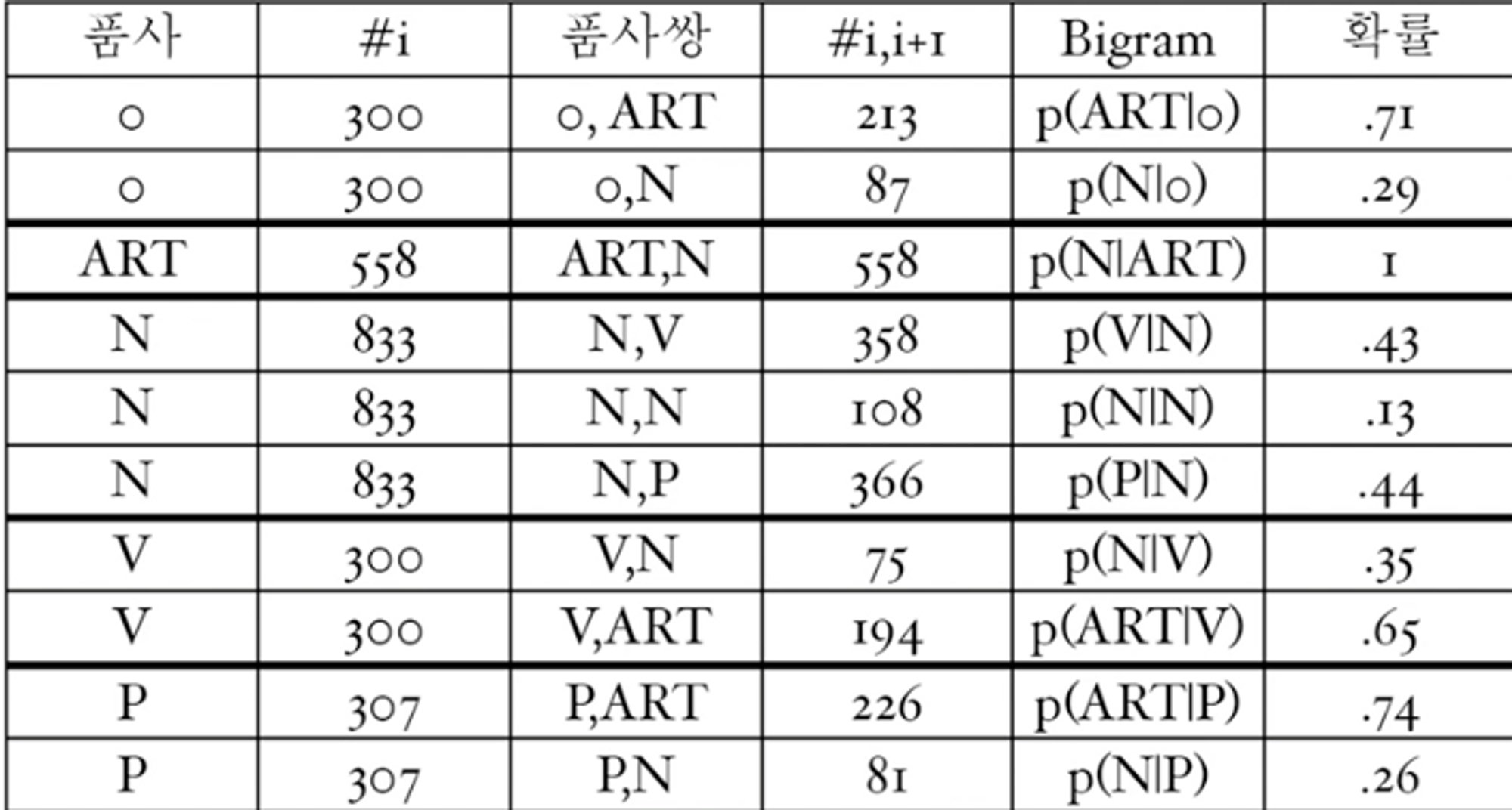
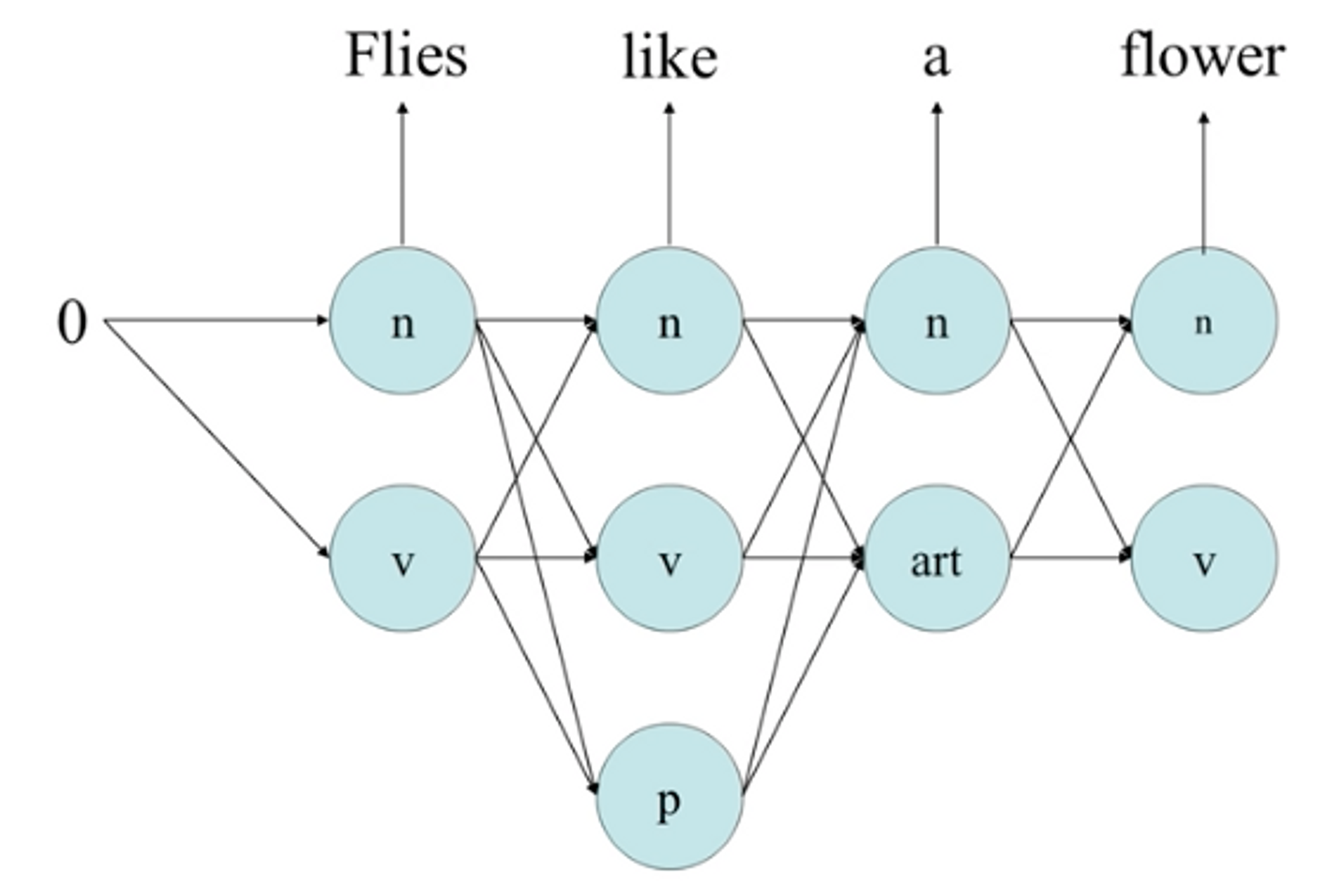
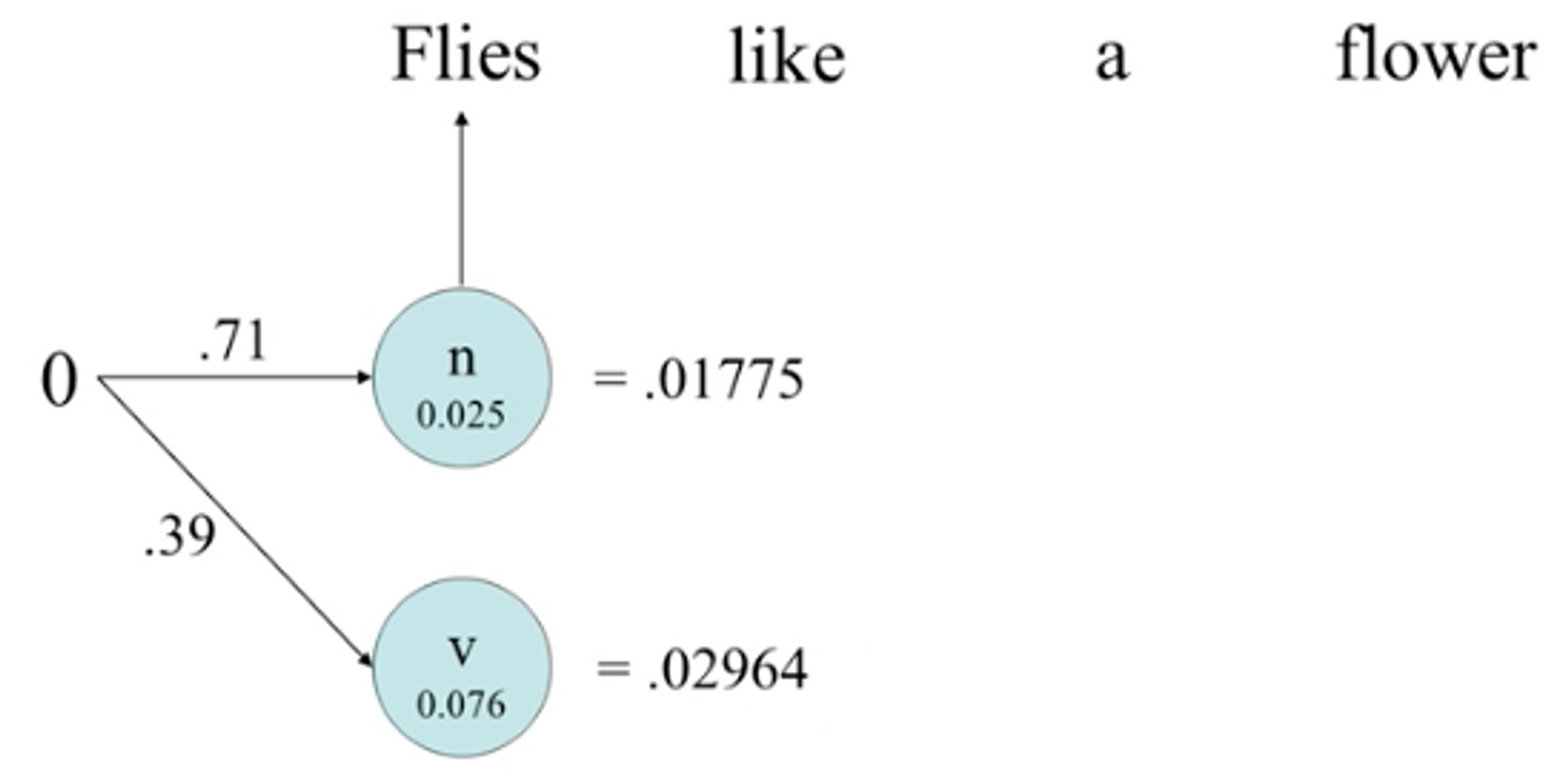
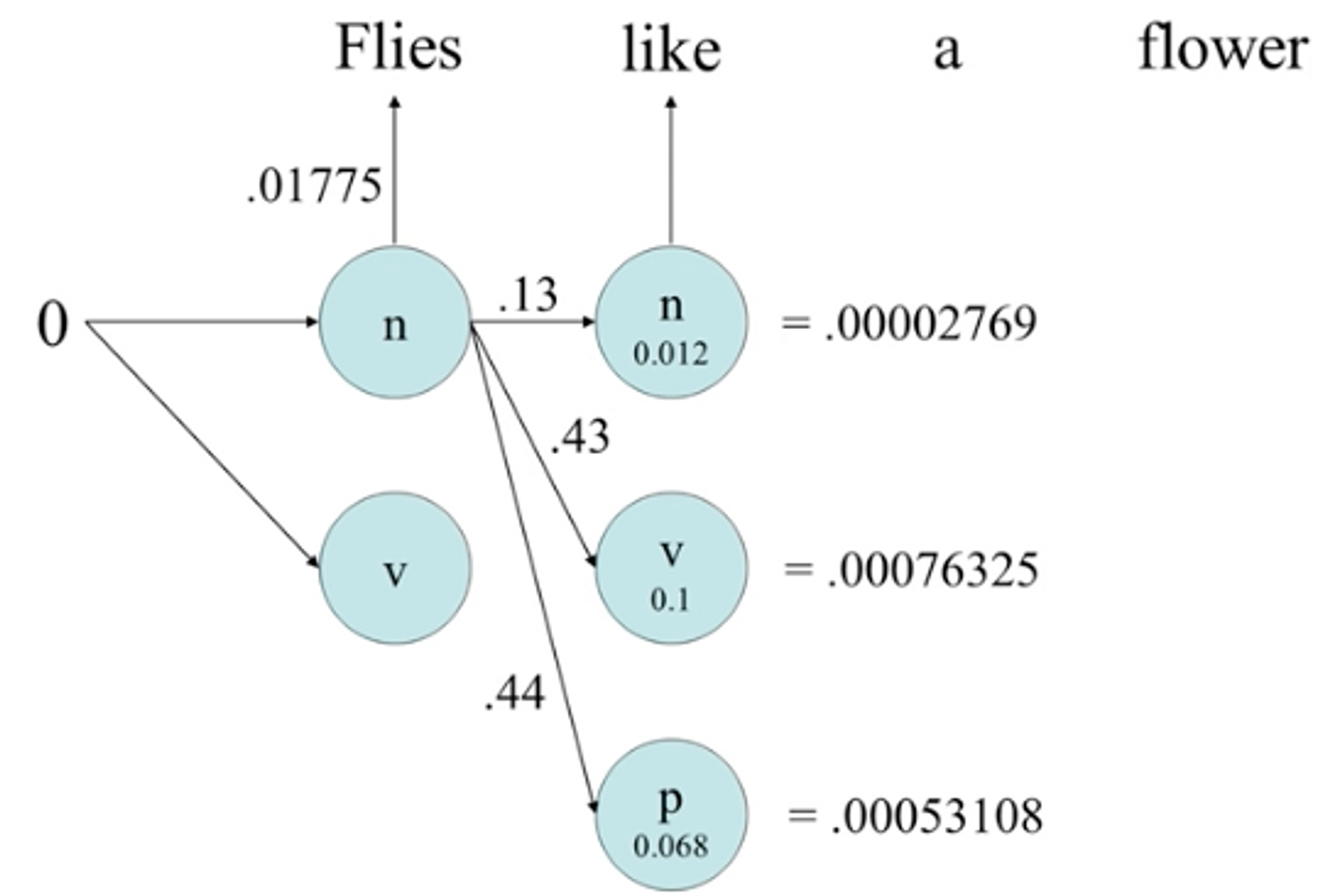
- 은닉 마코프 모델(HMM: Hidden Markov Model)태그가 부착된 대량의 코퍼스가 주어지면 태깅에 적합한 모델을 선정하고 코퍼스에서 추출된 통계정보 이용.주어진 문장에서 형태소의 품사 태그 정보를 숨긴채로 확률 정보를 이용해 가장 가능성이 높은 경로를 찾음.
- 단어가 어떤 품사냐 를 고려해 찾지 전체 문맥정보는 고려되지 않음.
- 대량의 코퍼스에 태그가 부착되어야하는 단점이 있지만 통계정보 추출이 용이, 자동추출가능.
- 대표적으로 어휘 확률만을 이용하는 반법으로 확률이 높은것을 선택.가장 성능 좋은 접근 방법.


- 딥러닝 기반의 접근법
방대한 데이터로 학습. 접근방법이 네트워크 구조를 심층으로 만들어 구조 내에서 학습 과정에서 특징들이 내부적으로 추출되도록 만듬.
언어처리에서 딥러닝의 효과
- 데이터로부터 특징을 자동으로 학습
- 폭넓은 문맥 정보를 다룰 수 있음
- 모델이 적합한 출력을 다루기가 간단함
- 언어 + 음성,사진 데이터를 결합하여 처리 가능
*접근법에 따른 단점 몰아보기
-규칙기반: 수동으로. 전문가필요. 노력,시간, 비용 많이듬. 정해진 규칙 외에는 해결안됨.
-통계기반: 앞의 단어의 태깅 정보에 따라 결정되어 문맥을 고려하지는 못함.
'IT > 자연어처리' 카테고리의 다른 글
| [자연어처리] 7.의미 분석 (1) | 2023.02.02 |
|---|---|
| [자연어처리] 6.구문 분석 (0) | 2023.02.02 |
| [자연어처리] 4. 텍스트의 전처리 (0) | 2023.02.02 |
| [자연어처리] 3. 언어학의 기본 원리 (1) | 2023.02.02 |
| [자연어처리] 2. 자연어처리를 위한 수학-복습3 (0) | 2023.02.02 |



