
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 노드
- 편미분
- 회귀분석
- 파라미터
- 자연어처리
- 단층 퍼셉트론
- 신경망
- DB
- lost function
- DBMS
- 파이썬 딥러닝
- 딥러닝 교차엔트로피
- 딥러닝 교차 엔트로피
- 자료구조
- 뇌를 자극하는 알고리즘
- 엔트로피
- 선형 리스트
- 순차 자료구조
- 오퍼랜드
- 단층퍼셉트론
- 확률분포
- 딥러닝
- 리스트
- 퍼셉트론
- 자료구조 알고리즘
- 인공지능
- 연결 자료구조
- 컴퓨터구조
- 교차 엔트로피
- 파이썬 날코딩으로 알고 짜는 딥러닝
- Today
- Total
YZ ZONE
[자연어처리] 4. 텍스트의 전처리 본문
비정형 데이터(unstructured Data)
-형태와 구조가 다른 구조화 되지 않은 데이터. 그림, 영상, 음성, 문서
-비정형 데이터의 오류를 수정하는 과정을 전처리 과정이라 함
-실세계 데이터는 대부분 가공되어 있지 않은 비정형 데이터라 전처리 과정을 필수적.

텍스트 문서의 변환
-파일로부터 텍스트를 추출하는 것이 전처리의 첫 단계
-일반 문서들은 사람이 읽기 간편하나 파일 형식에 따라 저장 방법이 달라 시스템이 읽기 힘듬.
-사람: 해당 텍스트가 하나의 문장이며 그 내용을 쉽게 파악 가능
-시스템: 문서파일을 해당 형식에 따라 크롤링(Crawling)하면 다음과 같이 다르게 읽힘.
-’문서파일’→ ‘문서’ 작업 수행 - 목표 언어의 어휘만 남기고 기타 텍스트(특수문자, 타 언어)들은 날려야함.
-특수문자 제거, 관련 없는 특수 커맨드 or 코딩을 규칙적으로 제거, PDF는 텍스트를 문장 단위로만 끊어 줄 바꿈 무시. ⇒ 문장의 경계 인식해야함.

띄어쓰기 교정 방법
용도
-의미분절: 각 단어 및 조사간 구분을 명확하게 해줘 간편한 프로세싱(처리) 가능
-가독성: 문맥상 의미파악
-의미혼용 방지: 띄어쓰기의 부재는 문자열 처리 시 오류율이 높아짐. ex.아버지가방에들어가신다.
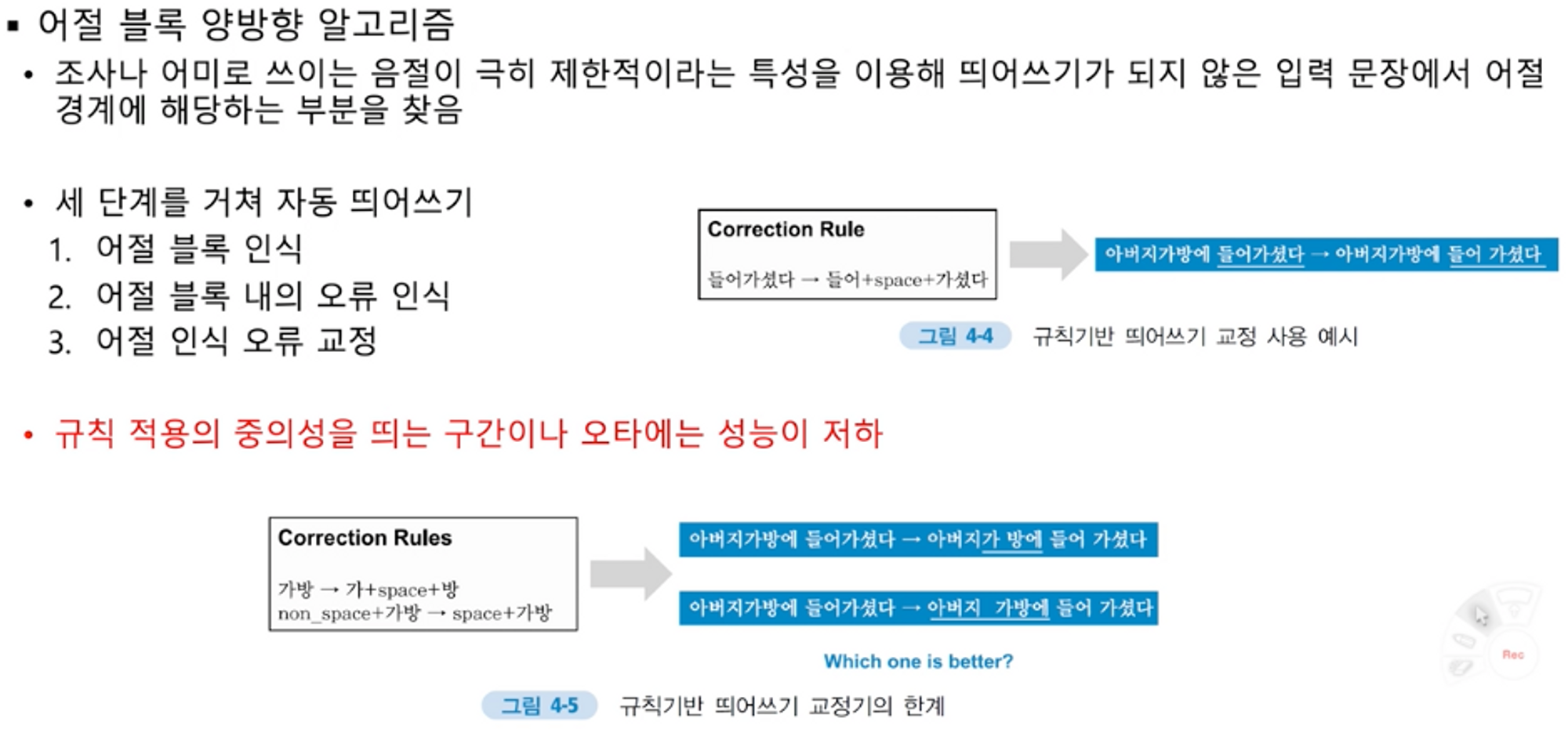
1.규칙기반
형태소 분석기 사용.
규칙: 어휘지식, 규칙, 오류 유형 등 휴리스틱(사람의 경험을 바탕으로=맘대로) 규칙을 이용
장점: 높은 정확도
단점
- 규칙이 있을때 해당될때만 가능. 규칙에 포함안되면 안됨.
-무한한 경우의 수(문장의 무한한 길이)를 고려해 모든 규칙을 사람이 만드는것은 불가능
-복잡한 분석과정. 비용 큼
-시스템 유지보가 어려움
-손수 제작이라 성능이 높을 수록 시간, 인적비용 증가
2.통계 확률기반
말뭉치를 기계적인 계산 과정을 통해 교정. 옳을 확률이 높은 후보로 교정함.
장점: 구현 용이. 미등록어도 분석 가능.
단점: 정확도 ,오류율 높음. 대량의 학습 데이터를 요구(말뭉치 구하기 어려움).
철자 및 맞춤법 교정
정확한 의미전송 및 정보교환에 필요. 띄어쓰기 교정의 연장선(비슷). 의미혼용 방지 및 정보전달 실패 방지를 위해
형태소 분석기로 텍스트 내 오류 감지→ 수정
-오타: 삽입(문자 추가), 생략, 대체(다른문자 침), 순열(순서 바뀜)
1.규칙기반
띄어쓰기 교정과 장단점 같음.
어절을 형태소들로 분절하는 ‘형태소 분석기’를 사용한 방식 존재
맞춤법 교정 과정: 전처리→ 품사태깅→ 규칙탐색→교정 결과 제시
2.확률기반
오타가 날 확률을 확률적(수식)으로 계산.
'IT > 자연어처리' 카테고리의 다른 글
| [자연어처리] 6.구문 분석 (0) | 2023.02.02 |
|---|---|
| [자연어처리] 5. 어휘 분석 (0) | 2023.02.02 |
| [자연어처리] 3. 언어학의 기본 원리 (1) | 2023.02.02 |
| [자연어처리] 2. 자연어처리를 위한 수학-복습3 (0) | 2023.02.02 |
| [자연어처리] 2. 자연어처리를 위한 수학-복습2 (0) | 2023.02.02 |



