
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 편미분
- 자료구조 알고리즘
- 회귀분석
- 리스트
- DB
- 뇌를 자극하는 알고리즘
- 딥러닝
- 순차 자료구조
- DBMS
- 오퍼랜드
- 파이썬 날코딩으로 알고 짜는 딥러닝
- 딥러닝 교차 엔트로피
- 단층퍼셉트론
- 확률분포
- 노드
- lost function
- 인공지능
- 교차 엔트로피
- 신경망
- 연결 자료구조
- 선형 리스트
- 자연어처리
- 엔트로피
- 파이썬 딥러닝
- 컴퓨터구조
- 딥러닝 교차엔트로피
- 단층 퍼셉트론
- 자료구조
- 파라미터
- 퍼셉트론
- Today
- Total
YZ ZONE
[ 컴퓨터구조 ] 2.3 명령어 파이프라이닝 본문
[ 명령어 파이프라이닝(instruction pipelining) ]
▣ 명령어 파이프라이닝이란?
▪ CPU의 프로그램 처리 속도를 높이기 위하여 CPU 내부 하드웨어를 여러 단계로 나누어 동시에 처리하는 기술
▣ 2단계 명령어 파이프라인(two-stage instruction pipeline) ▪ 명령어를 실행하는 하드웨어를 인출 단계(fetch stage)와 실행 단계
(execute stage)라는 두 개의 독립적인 파이프라인 모듈로 분리
▪ 두 단계들에 동일한 클록을 가하여 동작 시간을 일치시키면,
➢첫 번째 클록 주기에서는 인출 단계가 첫 번째 명령어를 인출
➢두 번째 클록 주기에서는 인출된 첫 번째 명령어가 실행 단계로 보내져 서 실행되며, 그와 동시에 인출 단계는 두 번째 명령어를 인출(선인출 (prefetch))
[ 2단계 명령어 파이프라인과 시간 흐름도 ]

* 속도향상(Sp) = 6/4 = 1.5배. 실행되는 명령어 수 증가 시, Sp = 2배에 접근
▣ 장점
▪ 2-단계 파이프라인을 이용하면 명령어 처리 속도가 두 배 향상(이론)
▣ 문제점
▪ 두 단계의 처리 시간이 동일하지 않으면 두 배의 속도 향상을 얻지 못
함(파이프라인 효율 저하)
▣ 해결책
▪ 파이프라인 단계를 세분하여, 각 단계의 처리 시간을 (거의) 같아지도
록함
➢파이프라인 단계의 수를 늘리면 전체적으로 속도향상(speedup)이 더 높 아짐
[ 4단계 명령어 파이프라인 ]
▣ 명령어 인출(IF) 단계
▪ 다음 명령어를 기억장치로부터 인출
▣ 명령어 해독(ID) 단계
▪ 해독기(decoder)를 이용하여 명령어를 해석
▣ 오퍼랜드 인출(OF) 단계
▪ 기억장치로부터 오퍼랜드를 인출
▣ 실행(EX) 단계
▪ 지정된 연산을 수행
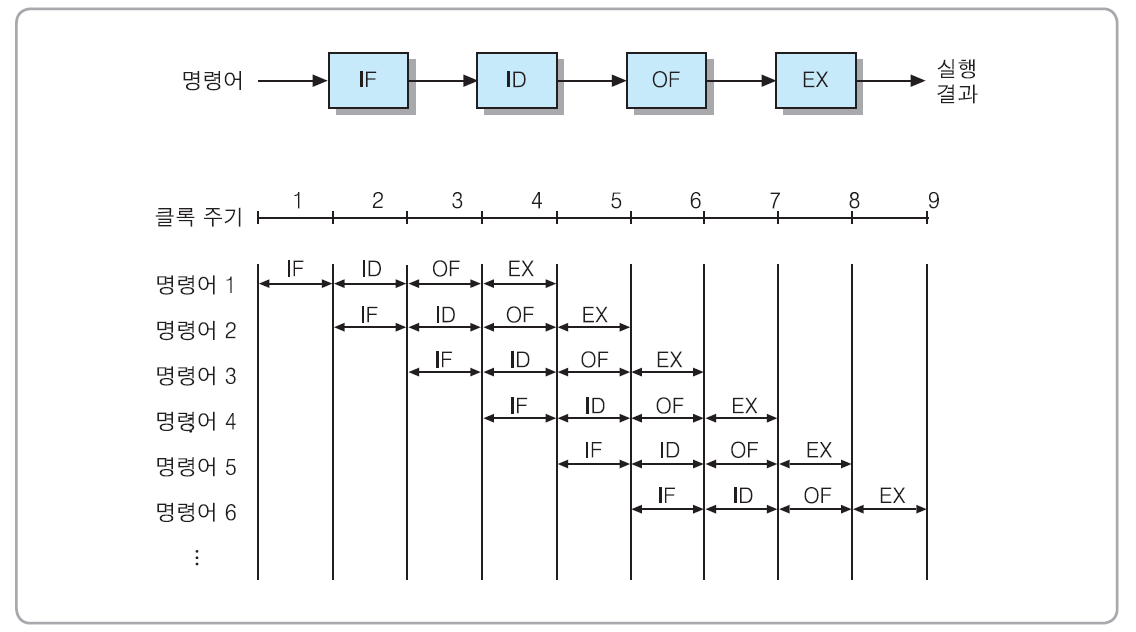
[ 파이프라인에 의한 전체 명령어 실행 시간 ]
▣ 파이프라인에 의한 전체 명령어 실행 시간(Tk):
▪ 파이프라인 단계 수 = k
▪ 실행할 명령어들의 수 = N
▪각 파이프라인 단계가 한 클록 주기씩 걸린다고 가정

➢즉, 첫 번째 명령어를 실행하는데 k 주기가 걸리고, 나머지 (N-1) 개의 명령어들은 각각 한 주기씩만 소요
➢파이프라인 되지 않은 경우의 N 개의 명령어들을 실행 시간 (T1):
T1 = k × N
▣ 파이프라인에 의한 속도 향상(speedup)

[ 파이프라인의 효율 저하 요인들 ]
▣ 모든 명령어들이 파이프라인 단계들을 모두 거치지는 않음
▪ 어떤 명령어에서는 오퍼랜드를 인출할 필요가 없지만, 파이프라인의 하드웨어를 단순화시키기 위해서는 모든 명령어가 네 단계들을 모두 통과하도록 해야 한다
▣ 파이프라인의 클록은 처리 시간이 가장 오래 걸리는 단계를 기준으로 결정된다
▣ IF 단계와 OF 단계가 동시에 기억장치를 액세스하는 경우 에, 기억장치 충돌(memory conflict)이 일어나면 지연이 발생 한다
▣ 조건 분기(conditional branch) 명령어가 실행되면, 미리 인 출하여 처리하던 명령어들이 무효화된다
[ 조건 분기가 존재하는 경우의 시간 흐름도 ]
[예] 명령어 3: JZ 12 ; jump (if zero) to address 12
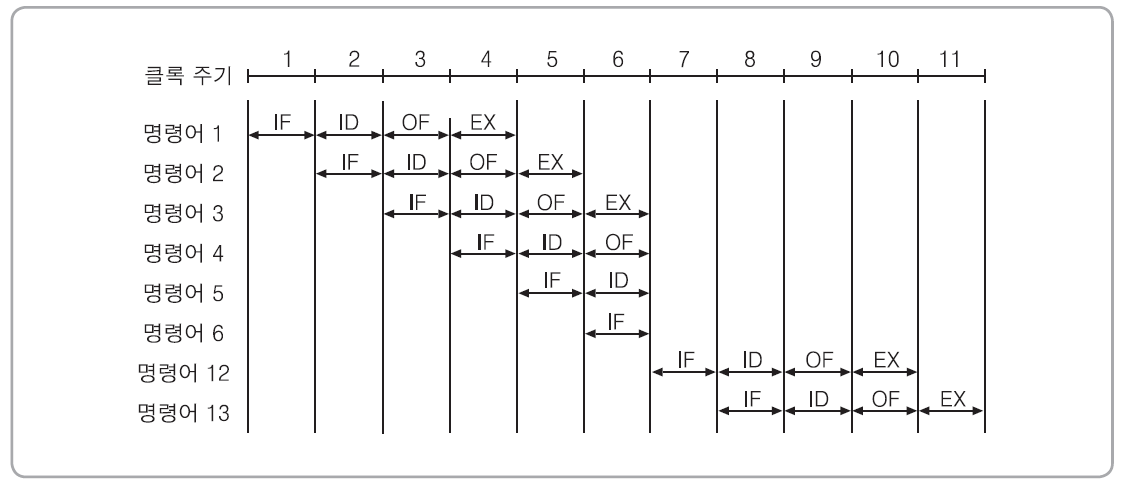
[ 분기 발생에 의한 성능 저하의 최소화 방법 ]
▣ 분기 예측(branch prediction)
▪ 분기가 일어날 것인 지를 예측하고, 그에 따라 명령어를 인출하는 확률적 방법
▪ 분기 역사 표(branch history table) 이용하여 최근의 분기 결과를 참조
▣ 분기 목적지 선인출(prefetch branch target)
▪ 조건 분기가 인식되면, 분기 명령어의 다음 명령어뿐만 아니라 분기의 목적지 명령어도 함께 인출하여 실행하는 방법(조건 확인 결과에 따라 명령어를 선택하여 실행)
▣ 루프 버퍼(loop buffer) 사용
▪ 파이프라인의 명령어 인출 단계에 포함되어 있는 작은 고속 루프 버퍼에 가장 최 근 인출된 n개의 명령어들을 순서대로 저장해두는 방기억장치인법
▣ 지연 분기(delayed branch)
▪ 분기 명령어의 위치를 재배치함으로써 파이프라인의 성능을 개선하는 방법
[ 상태 레지스터(status register) ]
▣ 조건 분기 명령어에서 사용하는 조건들은 CPU 내부의 상태 레지스 터에 저장
▣ 명령어 실행 결과에 따른 조건 플래그(condition flag)들 저장
▣ CPU는 실행 사이클 동안에 조건 분기 명령어가 지정하는 플래그 의 값을 검사하여 분기 여부를 결정함
▣ 조건 플래그의 종류
▪ 부호(S) 플래그
➢직전에 수행된 산술연산 결과값의 부호 비트를 저장(양수: 0, 음수: 1)
▪ 영(Z) 플래그
➢연산 결과값이 0 이면, 1로 세트
▪ 올림수(C) 플래그
➢덧셈이나 뺄셈에서 올림수(carry)나 빌림수(borrow)가 발생한 경우에 1로 세트
▪ 동등(E) 플래그
➢두 수를 비교한 결과가 같게 나왔을 경우에 1로 세트
▪ 오버플로우(V) 플래그
➢산술 연산 과정에서 오버플로우가 발생한 경우에 1로 세트
▪ 인터럽트(I) 플래그
➢인터럽트 가능(interrupt enabled) 상태이면, 0으로 세트 ➢인터럽트 불가능(interrupt disabled) 상태이면, 1로 세트
▪ 슈퍼바이저(P) 플래그
➢CPU의 실행 모드가 슈퍼바이저 모드(supervisor mode)이면, 1로 세트 ➢사용자 모드(user mode)이면, 0으로 세트

[ 슈퍼스칼라(superscalar) ]
▣ CPU의 처리 속도를 더욱 높이기 위하여 내부에 두 개 혹은 그 이상의 명령어 파이프라인들을 포함시킨 구조
▣ 매 클록 주기마다 각 명령어 파이프라인이 별도의 명령어를 인출하여 동시에 실행할 수 있기 때문에, 이론적으로는 프로그 램 처리 속도가 파이프라인의 수만큼 향상 가능
▣ 파이프라인의 수 = m : m-way 슈퍼스칼라
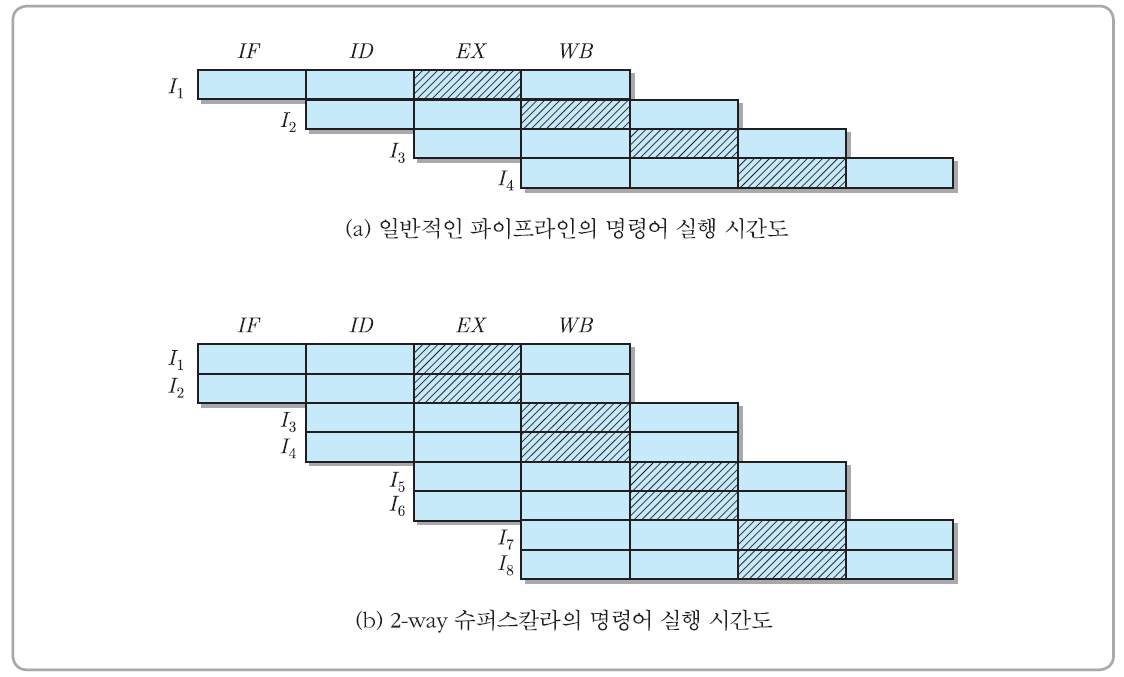
[ 슈퍼스칼라에 의한 속도향상(speedup: Sp) ]
▣ 단일 파이프라인에 의한 실행 시간 (N : 실행할 명령어 수)

▣ m-way 슈퍼스칼라에 의한 실행 시간
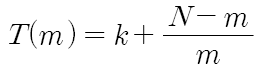
▣ 속도 향상
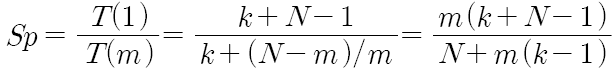
▣ 명령어 수 N→∞, Sp→m
▣ 슈퍼스칼라의 속도 저하 (Sp<m) 요인 :
▪ 명령어들 간의 데이터 의존 관계
▪ 하드웨어(레지스터, 캐시, 기억장치,등) 이용에 대한 경합 발생
▪➔동시 실행 가능한 명령어 수 < m
▣ 해결책
▪ 명령어 실행 순서 재배치
➢명령어들 간의 데이터 의존성 제거
▪ 하드웨어 추가(중복) 설치
➢하드웨어(레지스터, 캐시, 등)에 대한 경합 감소
[ 듀얼-코어 및 멀티-코어 ]
▣ CPU 코어(core)
▪ 명령어 실행에 필요한 CPU 내부의 핵심 하드웨어 모듈(슈퍼스칼라 H/W, ALU, 레지스터 등)
▣ 멀티-코어 프로세서(multi-core processor)
▪ 여러 개의 CPU 코어들을 하나의 칩에 포함시킨 프로세서
➢듀얼-코어(dual-core): 두 개의 CPU 코어 포함
➢쿼드-코어(quad-core): 네 개의 CPU 코어 포함
➢헥사-코어(hexa-core), 옥타-코어(octa-core)도 출시 중
▣ 칩-레벨 다중프로세서(chip-level multiprocessor) 혹은 단일-칩 다중프로세서(multiprocessor-on-a-chip)이라고도 부름
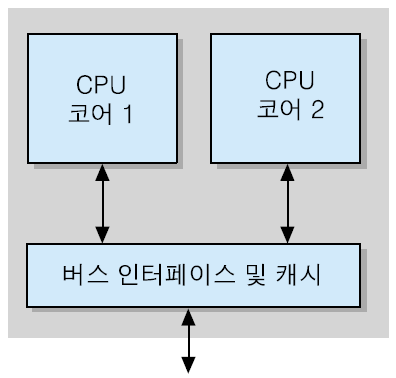
▣ 듀얼-코어 프로세서
▪ 단일-코어 슈퍼스칼라 프로세서에 비하여 2배의 속도 향상 기대
▪ 코어들은 내부 캐시와 시스템 버스 인터페이스만 공유
▪ 코어 별로 독립적 프로그램 실행 → 멀티-태스킹(multi-tasking) 혹은 멀티-스레딩(multi-threading) 지원
▣ 멀티-스레딩
▪ 스레드(thread): 독립적으로 실행될 수 있는 최소 크기의 프로그램 단위
▪ 단일-스레드 모델(그림 (a)): 각 코어가 스레드를 한 개씩 처리
➢처리 중의 스레드에 대한 시스템 상태, 데이터 및 주소 정보를 레지스터 세트(register set: RS)에 저장
➢RS: 프로그램 카운터(PC), 스택 포인터(SP), 상태 레지스터, 데이터 레지스터, 주소 레지스터, 등

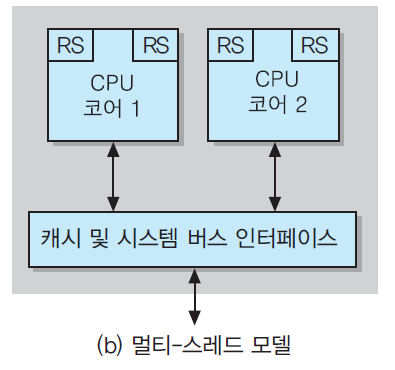
▣ 멀티-스레드 모델(그림 (b)):
▪ 각 코어는 두 개의 RS들을 포함하며, 스레드를 두 개씩 처리
▪ 두 스레드들이 CPU 코어의 H/W 자원들(ALU, 부동소수점유니트, 온-칩 캐시,TLB, 등)을 공유
▪ 처리 중의 각 스레드에 대한 시스템 상태, 데이터 및 주소 정보는 서로 다른 레지스터 세트(RS)에 저장
▣ 듀얼-코어 멀티-스레드 프로세서
▪ ‘두 개의 물리적 프로세서(physical processor)들이 네 개의 논리적 프로세서(logical processor)들로 구성되어 있다’라고 정의하기도 함 [INTi17 참조]
▣ 멀티-코어 멀티-스레딩 프로세서의 사례
▪ Intel i7-8500Y : 2-코어 4-스레드 프로세서
▪ Intel i7-8565U : 4-코어 8-스레드 프로세서
'IT > 컴퓨터구조' 카테고리의 다른 글
| [ 컴퓨터구조 ]2.4.2 명령어 세트 (0) | 2023.02.05 |
|---|---|
| [ 컴퓨터구조 ] 2.4 명령어 세트 (0) | 2023.02.05 |
| [컴퓨터구조] 2.2 명령어 실행 (0) | 2023.02.04 |
| [컴퓨터구조] 2.1 CPU의 기본 구조 (0) | 2023.02.04 |
| [ 컴퓨터구조 ] 1.4.2 컴퓨터 구조의 발전 과정 (0) | 2023.02.04 |



