
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 리스트
- 노드
- 파이썬 딥러닝
- 파라미터
- 순차 자료구조
- 엔트로피
- 딥러닝 교차엔트로피
- 딥러닝 교차 엔트로피
- 자료구조
- 자료구조 알고리즘
- 뇌를 자극하는 알고리즘
- 교차 엔트로피
- 퍼셉트론
- 파이썬 날코딩으로 알고 짜는 딥러닝
- 자연어처리
- 단층퍼셉트론
- 확률분포
- DBMS
- 신경망
- 인공지능
- DB
- 오퍼랜드
- 단층 퍼셉트론
- 컴퓨터구조
- 선형 리스트
- 딥러닝
- 회귀분석
- 편미분
- lost function
- 연결 자료구조
Archives
- Today
- Total
YZ ZONE
[자연어처리] 10. 정보 추출 본문
정보추출?
비정형 또는 정형화된 텍스트에서 자동으로 구조화 된 정보를 추출하는 작업
비정형 텍스트에서 정보 추출하기 위해 규칙적이고 엔티티간의 의미적 관계를 포함하는 구조화된 데이터가 필요함
- 목적
문서 내 단어 간의 대상 관계를 파악하여 의미적 관계를 추출하고 이에 대해 응답하는 것을 중점을 둠
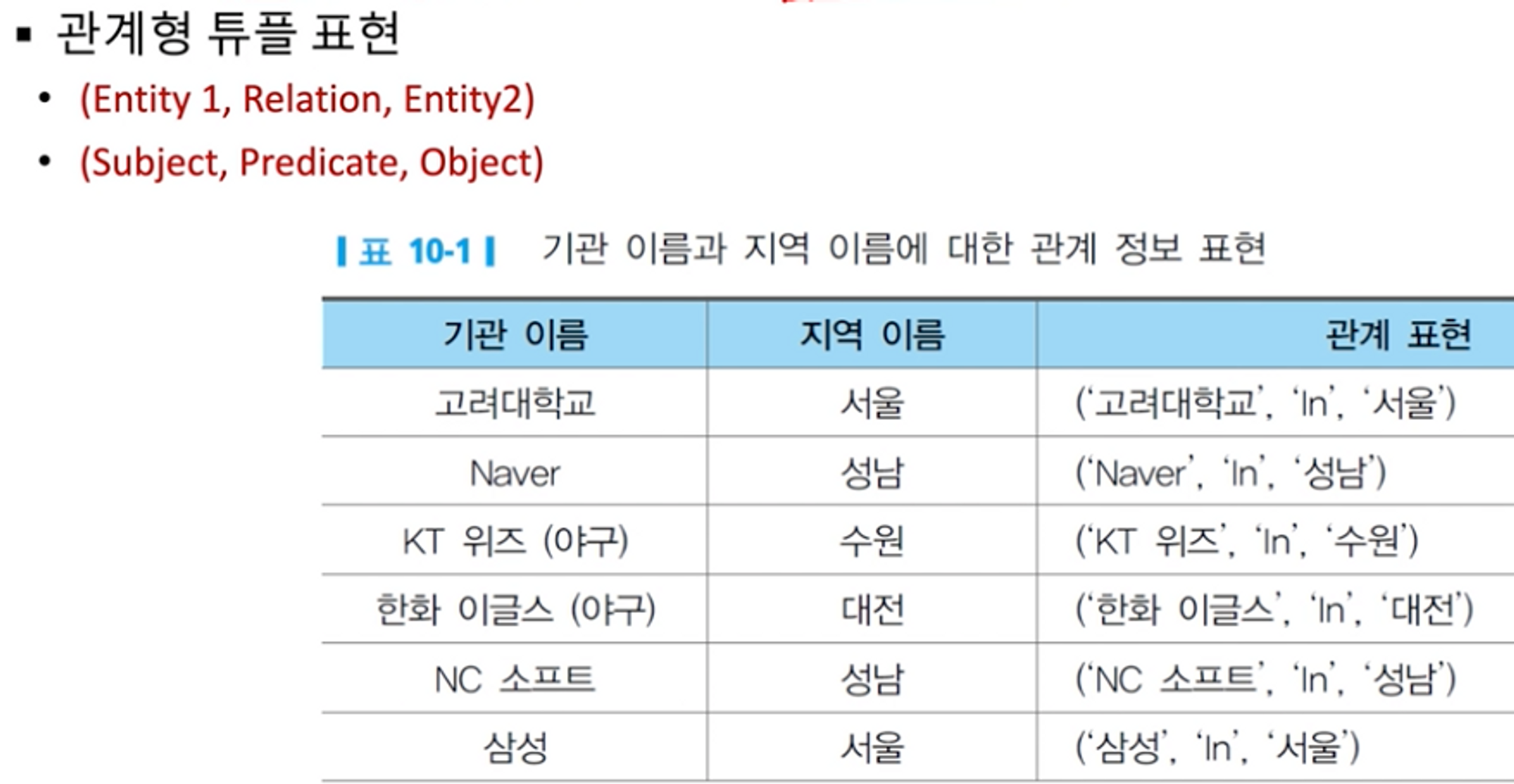
정보 추출의 학습 방법
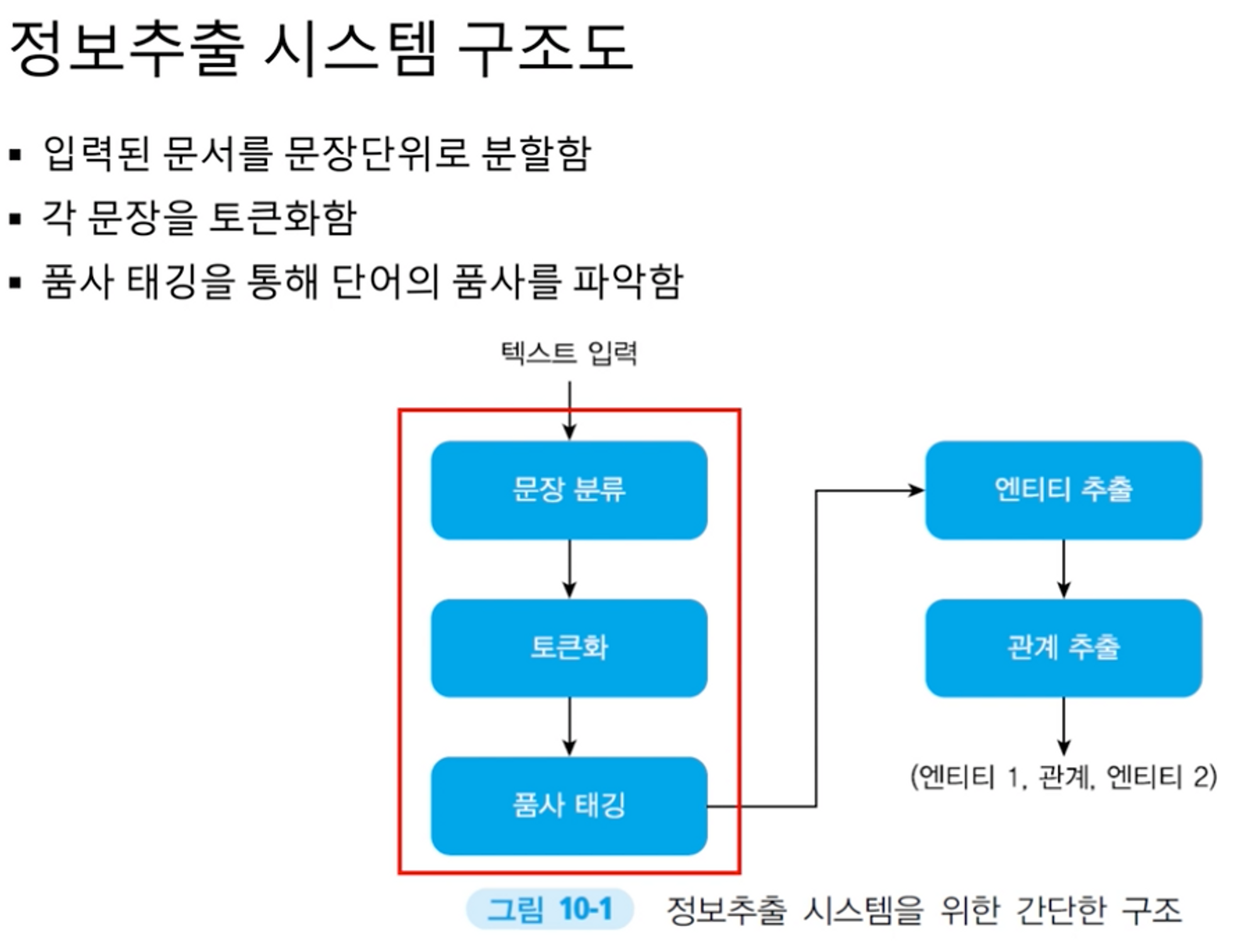

정보추출의 주요 하위 작업
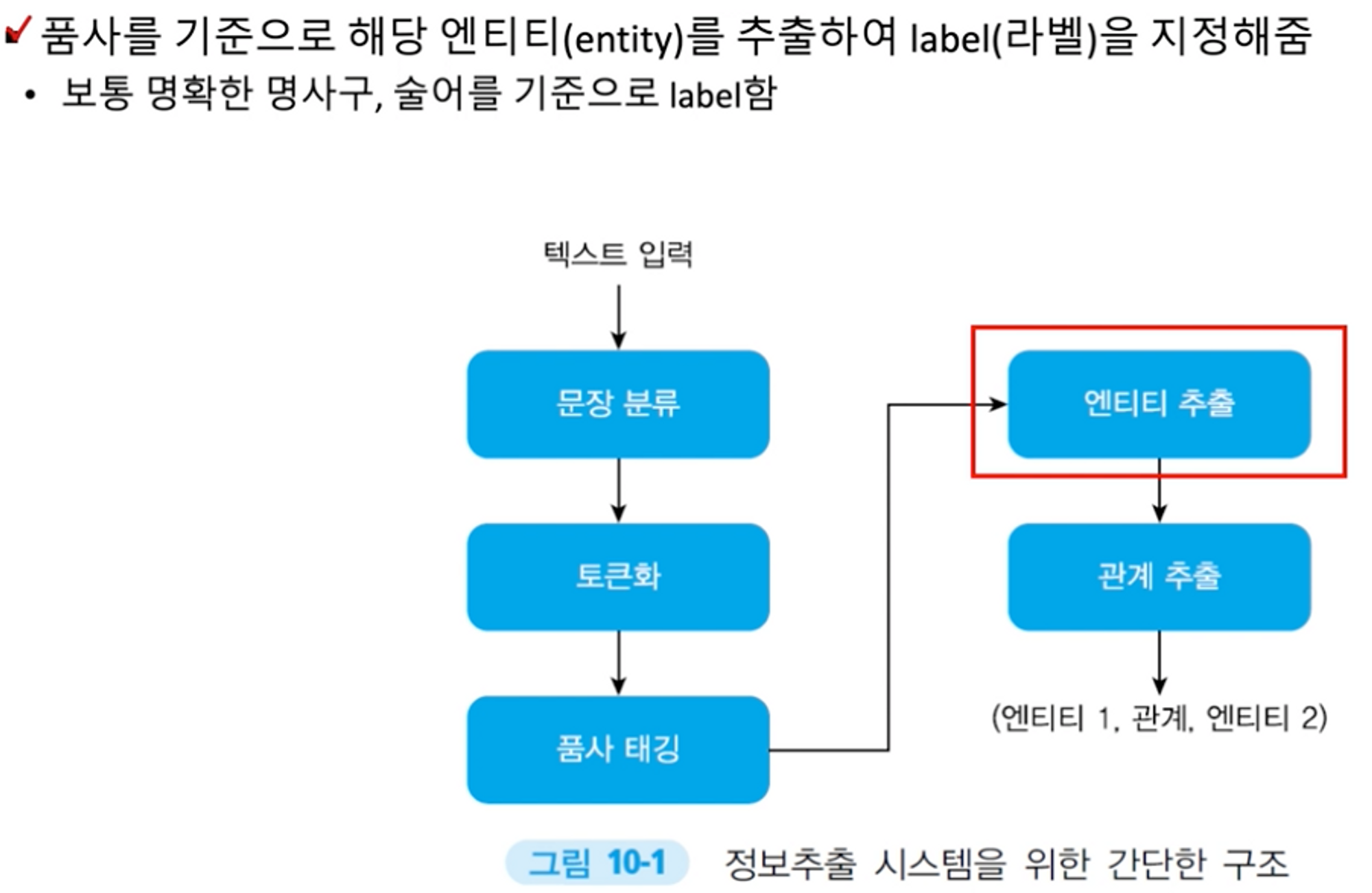
- NER(Named Entity Recognition): 감지된 엔티티 이름(사랑과 조직의 경우), 장소이름, 임시 표현 및 특정 유형의 숫자 표현 인식 등 특정 유형의 개체에 대한 참조를 식별하는 것.
- 상호참조(Coreference Resolution): 이전 단계에서 추출된 엔티티 유형을 기반으로 엔티티 간의 상호 참조 및 wikipedia 링크 찾아 관련된 모든 용어를 찾는다
- 관계 추출(Relation Extraction): 텍스트에서 엔티티 간의 관계를 식별하고 구조화된 정보로 나타내는 중요한 하위 작업
추출된 정보는 사용자에 의해 정의된 객체(Object)의 형태로 제공
관계추출
각 엔티티의 유형을 감지하며, 엔티티 간의 관계를 식별하고 유형을 추출하는 것이 목표

정보추출(관계추출)접근법 - 규칙기반 접근법
문장에서 문법적 속성에 대한 규칙 세트를 정의한 다음 규칙을 사용하여 정보를 추출

정보추출(관계추출)접근법 - 기계학습 기반 접근법
- 지도학습 Supervised learning
문장에서 엔티티1과 엔티티2의 관계가 있는지 여부 확인
단점: 모델을 훈련시키기 위해 많은 label된 데이터가 필요 즉 관계가 잘 들어나있는 데이터셋 필요.
- Semi-supervised learning
lable된 데이터가 어느정도는 있는데 충분하지 않을때 lable된 데이터를 기준으로 unlabled 된 데이터를 lable시키고
'IT > 자연어처리' 카테고리의 다른 글
| [자연어처리] 11. 자연어 질의응답 시스템 (0) | 2023.02.03 |
|---|---|
| [자연어처리] 9. 언어모델 Language Model, LM (0) | 2023.02.03 |
| [자연어처리] 8.개체명 인식 (0) | 2023.02.03 |
| [자연어처리] 7.의미 분석 (1) | 2023.02.02 |
| [자연어처리] 6.구문 분석 (0) | 2023.02.02 |
'IT/자연어처리' Related Articles
more

